
Hi, this is Fengtao.
I am currrently a PhD student of the Department
of Computer Science and Engineering (CSE) at
the Hong Kong University of Science and Technology
(HKUST),
supervised by Prof. Hao CHEN.
Before that, I received the Master's degree from the
School of Big Data
and Software
Engineering, Chongqing University, supervised
by Prof. Sheng HUANG, in 2022.
Previously, I
received the Bachelor's degree from Chongqing University, in 2019.
Google Scholar
Github
ORCID
Research Gate
Latest News
-
[02/2024] One papers on computational pathology was accepted by CVPR 2024.
-
[01/2024] Our paper on multimodal and explainable AI for cervical cancer diagnosis was accepted by Nature Communications.
-
[07/2023] Two papers were accepted by ICCV 2023. One of them was accepted as Oral.
Education
Sept. 2015 - Jun. 2019
Bachelor in Software Engineering
Chongqing University
Chongqing, China
Sept. 2019 - Jun. 2022
Master in Software Engineering
Chongqing University
Chongqing, China
Sept. 2022 - Present
PhD in Computer Science and Engineering
The Hong Kong University of Science and Technology
Hong Kong, China
Research Interests
-
Multimodal
Learning -
Computational
Pathology -
Survival
Analysis -
Multi-label
Classification
Publications

Cohort-Individual Cooperative Learning for Multimodal Cancer Survival Analysis
Huajun Zhou*, Fengtao Zhou, Hao Chen#
Recently, we have witnessed impressive achievements in cancer survival analysis by integrating multimodal data, e.g., pathology images and genomic profiles. However, the heterogeneity and high dimensionality of these modalities pose significant challenges for extracting discriminative representations while maintaining good generalization. In this paper, we propose a Cohortindividual Cooperative Learning (CCL) framework to advance cancer survival analysis by collaborating knowledge decomposition and cohort guidance. Specifically, first, we propose a Multimodal Knowledge Decomposition (MKD) module to explicitly decompose multimodal knowledge into four distinct components: redundancy, synergy and uniqueness of the two modalities. Such a comprehensive decomposition can enlighten the models to perceive easily overlooked yet important information, facilitating an effective multimodal fusion. Second, we propose a Cohort Guidance Modeling (CGM) to mitigate the risk of overfitting task-irrelevant information. It can promote a more comprehensive and robust understanding of the underlying multimodal data, while avoiding the pitfalls of overfitting and enhancing the generalization ability of the model. By cooperating the knowledge decomposition and cohort guidance methods, we develop a robust multimodal survival analysis model with enhanced discrimination and generalization abilities. Extensive experimental results on five cancer datasets demonstrate the effectiveness of our model in integrating multimodal data for survival analysis. The code will be publicly available soon.
Read More
iMD4GC: Incomplete Multimodal Data Integration to Advance Precise Treatment Response Prediction and Survival Analysis for Gastric Cancer
Gastric cancer (GC) is a prevalent malignancy worldwide, ranking as the fifth most common cancer with over 1 million new cases and 700 thousand deaths in 2020. Locally advanced gastric cancer (LAGC) accounts for approximately two-thirds of GC diagnoses, and neoadjuvant chemotherapy (NACT) has emerged as the standard treatment for LAGC. However, the effectiveness of NACT varies significantly among patients, with a considerable subset displaying treatment resistance. Ineffective NACT not only leads to adverse effects but also misses the optimal therapeutic window, resulting in lower survival rate. Hence, it is crucial to utilize clinical data to precisely predict treatment response and survival prognosis for GC patients. Existing methods relying on unimodal data falls short in capturing GC's multifaceted nature, whereas multimodal data offers a more holistic and comprehensive insight for prediction. However, existing multimodal learning methods assume the availability of all modalities for each patient, which does not align with the reality of clinical practice. The limited availability of modalities for each patient would cause information loss, adversely affecting predictive accuracy. In this study, we propose an incomplete multimodal data integration framework for GC (iMD4GC) to address the challenges posed by incomplete multimodal data, enabling precise response prediction and survival analysis. Specifically, iMD4GC incorporates unimodal attention layers for each modality to capture intra-modal information. Subsequently, the cross-modal interaction layers explore potential inter-modal interactions and capture complementary information across modalities, thereby enabling information compensation for missing modalities. To enhance the ability to handle severely incomplete multimodal data, iMD4GC employs a ``more-to-fewer'' knowledge distillation, transferring knowledge learned from more modalities to fewer ones. To evaluate iMD4GC, we collected three multimodal datasets for GC study: GastricRes (698 cases) for response prediction, GastricSur (801 cases) for survival analysis, and TCGA-STAD (400 cases) for survival analysis. The scale of our datasets is significantly larger than previous studies. The iMD4GC achieved impressive performance with an 80.2% AUC on GastricRes, 71.4% C-index on GastricSur, and 66.1% C-index on TCGA-STAD, significantly surpassing other compared methods. Moreover, iMD4GC exhibits inherent interpretability, enabling transparent analysis of the decision-making process and providing valuable insights to clinicians. Furthermore, the flexible scalability provided by iMD4GC holds immense significance for clinical practice, facilitating precise oncology through artificial intelligence and multimodal data integration.
Read More
Development and validation of an interpretable model integrating multimodal information for improving ovarian cancer diagnosis
Nature Communications (NC, 2024)
Multiple instance learning (MIL) is the most widely used framework in computational pathology, encompassing sub-typing, diagnosis, prognosis, and more. However, the existing MIL paradigm typically requires an offline instance feature extractor, such as a pre-trained ResNet or a foundation model. This approach lacks the capability for feature fine-tuning within the specific downstream tasks, limiting its adaptability and performance. To address this issue, we propose a Re-embedded Regional Transformer (R2T) for re-embedding the instance features online, which captures fine-grained local features and establishes connections across different regions. Unlike existing works that focus on pre-training powerful feature extractor or designing sophisticated instance aggregator, RT is tailored to re-embed instance features online. It serves as a portable module that can seamlessly integrate into mainstream MIL models. Extensive experimental results on common computational pathology tasks validate that: 1) feature re-embedding improves the performance of MIL models based on ResNet-50 features to the level of foundation model features, and further enhances the performance of foundation model features; 2) the RT can introduce more significant performance improvements to various MIL models; 3) RT-MIL, as an RT-enhanced AB-MIL, outperforms other latest methods by a large margin. The code is available at:~\href{https://github.com/DearCaat/RRT-MIL}{https://github.com/DearCaat/RRT-MIL}.
Read More
Feature Re-Embedding: Towards Foundation Model-Level Performance in Computational Pathology
Wenhao Tang*, Fengtao Zhou*, Sheng Huang#, Xiang Zhu, Yi Zhang, Bo Liu
Computer Vision and Pattern Recognition Conference (CVPR, 2024)
Multiple instance learning (MIL) is the most widely used framework in computational pathology, encompassing sub-typing, diagnosis, prognosis, and more. However, the existing MIL paradigm typically requires an offline instance feature extractor, such as a pre-trained ResNet or a foundation model. This approach lacks the capability for feature fine-tuning within the specific downstream tasks, limiting its adaptability and performance. To address this issue, we propose a Re-embedded Regional Transformer (R2T) for re-embedding the instance features online, which captures fine-grained local features and establishes connections across different regions. Unlike existing works that focus on pre-training powerful feature extractor or designing sophisticated instance aggregator, RT is tailored to re-embed instance features online. It serves as a portable module that can seamlessly integrate into mainstream MIL models. Extensive experimental results on common computational pathology tasks validate that: 1) feature re-embedding improves the performance of MIL models based on ResNet-50 features to the level of foundation model features, and further enhances the performance of foundation model features; 2) the RT can introduce more significant performance improvements to various MIL models; 3) RT-MIL, as an RT-enhanced AB-MIL, outperforms other latest methods by a large margin. The code is available at:~\href{https://github.com/DearCaat/RRT-MIL}{https://github.com/DearCaat/RRT-MIL}.
Read More
Cross-modal Translation and Alignment for Survival Analysis
International Conference on Computer Vision (ICCV, 2023)
With the rapid advances in high-throughput sequencing technologies, the focus of survival analysis has shifted from examining clinical indicators to incorporating genomic profiles with pathological images. However, existing methods either directly adopt a straightforward fusion of pathological features and genomic profiles for survival prediction, or take genomic profiles as guidance to integrate the features of pathological images. The former would overlook intrinsic cross-modal correlations. The latter would discard pathological information irrelevant to gene expression. To address these issues, we present a Cross-Modal Translation and Alignment (CMTA) framework to explore the intrinsic cross-modal correlations and transfer potential complementary information. Specifically, we construct two parallel encoder-decoder structures for multi-modal data to integrate intra-modal information and generate cross-modal representation. Taking the generated cross-modal representation to enhance and recalibrate intra-modal representation can significantly improve its discrimination for comprehensive survival analysis. To explore the intrinsic cross-modal correlations, we further design a cross-modal attention module as the information bridge between different modalities to perform cross-modal interactions and transfer complementary information. Our extensive experiments on five public TCGA datasets demonstrate that our proposed framework outperforms the state-of-the-art methods. The source code has been released.
Read More
Multiple Instance Learning Framework with Masked Hard Instance Mining for Whole Slide Image Classification
Wenhao Tang*, Sheng Huang#, Xiaoxian Zhang, Fengtao Zhou, Yi Zhang, Bo Liu
International Conference on Computer Vision (ICCV, 2023)
The whole slide image (WSI) classification is often formulated as a multiple instance learning (MIL) problem. Since the positive tissue is only a small fraction of the gigapixel WSI, existing MIL methods intuitively focus on identifying salient instances via attention mechanisms. However, this leads to a bias towards easy-to-classify instances while neglecting hard-to-classify instances. Some literature has revealed that hard examples are beneficial for modeling a discriminative boundary accurately. By applying such an idea at the instance level, we elaborate a novel MIL framework with masked hard instance mining (MHIM-MIL), which uses a Siamese structure (Teacher-Student) with a consistency constraint to explore the potential hard instances. With several instance masking strategies based on attention scores, MHIM-MIL employs a momentum teacher to implicitly mine hard instances for training the student model, which can be any attention-based MIL model. This counter-intuitive strategy essentially enables the student to learn a better discriminating boundary. Moreover, the student is used to update the teacher with an exponential moving average (EMA), which in turn identifies new hard instances for subsequent training iterations and stabilizes the optimization. Experimental results on the CAMELYON-16 and TCGA Lung Cancer datasets demonstrate that MHIM-MIL outperforms other latest methods in terms of performance and training cost. The code is available at: https://github. com/DearCaat/MHIM-MIL.
Read More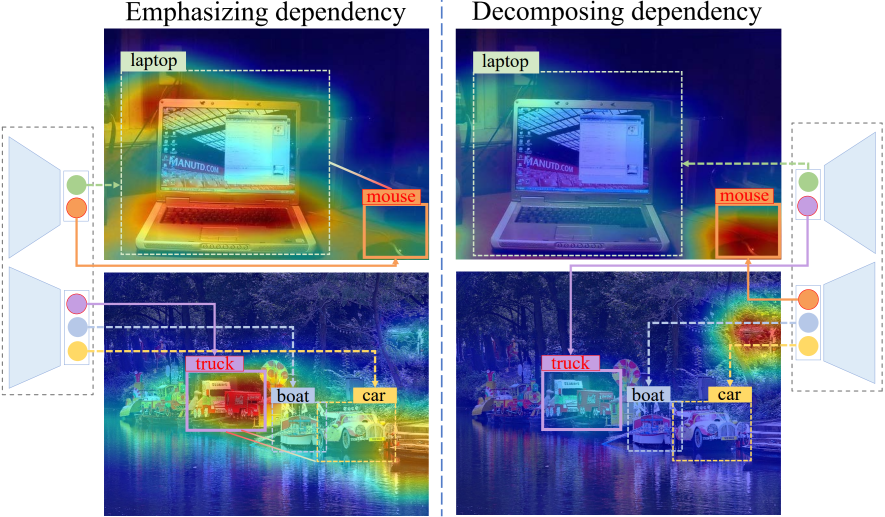
Boosting Multi-Label Image Classification with Complementary Parallel Self-Distillation
Jiazhi Xu*, Sheng Huang#, Fengtao Zhou, Luwen Huangfu, Daniel Zeng, Bo Liu
International Joint Conference on Artificial Intelligence (IJCAI, 2022)
Multi-Label Image Classification (MLIC) approaches usually exploit label correlations to achieve good performance. However, emphasizing correlation like co-occurrence may overlook discriminative features of the target itself and lead to model overfitting, thus undermining the performance. In this study, we propose a generic framework named Parallel Self-Distillation (PSD) for boosting MLIC models. PSD decomposes the original MLIC task into several simpler MLIC sub-tasks via two elaborated complementary task decomposition strategies named Co-occurrence Graph Partition (CGP) and Dis-occurrence Graph Partition (DGP). Then, the MLIC models of fewer categories are trained with these sub-tasks in parallel for respectively learning the joint patterns and the category-specific patterns of labels. Finally, knowledge distillation is leveraged to learn a compact global ensemble of full categories with these learned patterns for reconciling the label correlation exploitation and model overfitting. Extensive results on MS-COCO and NUS-WIDE datasets demonstrate that our framework can be easily plugged into many MLIC approaches and improve performances of recent state-of-the-art approaches. The explainable visual study also further validates that our method is able to learn both the category-specific and co-occurring features. The source code is released at https://github.com/Robbie-Xu/CPSD.
Read More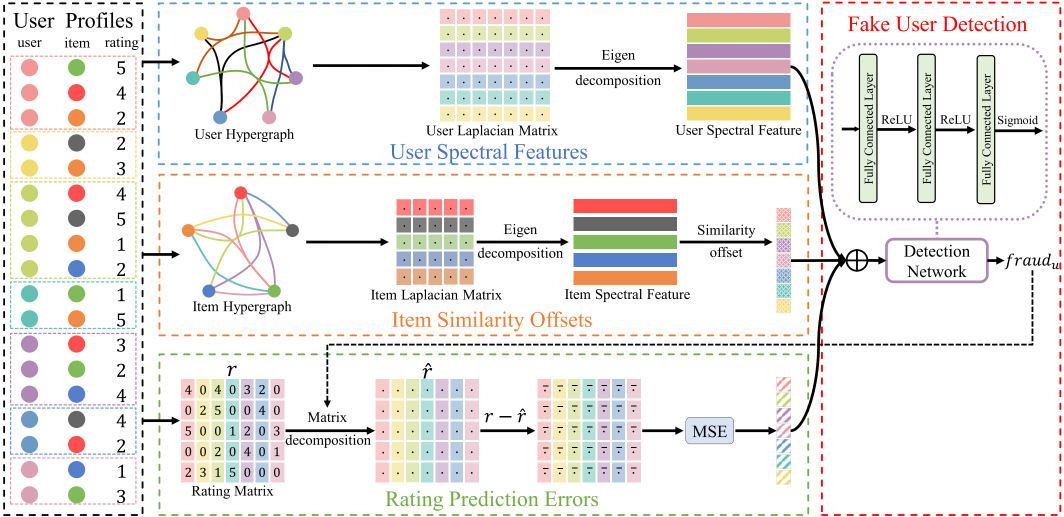
Fusing Hypergraph Spectral Features for Shilling Attack Detection
Hao Li*, Min Gao#, Fengtao Zhou, Yueyang Wang, Qilin Fan, Linda Yang
Journal of Information Security and Applications (JISA, 2021)
Recommender systems can effectively improve user experience, but they are vulnerable to shilling attacks due to their open nature. Attackers inject fake user profiles to destroy the security and reliability of the recommender systems. Therefore, it is crucial to detect shilling attacks effectively. The primitive detection models are feasible but costly because of the dependence on plenty of hand-engineered explicit features based on statistical measures. Even though the upgraded models based on learning embeddings of the implicit features are more general, they fail to take some distinct features in distinguishing fake users into consideration. Moreover, these primitive and upgraded models are difficult to capture the high order relationships between users and items as the models usually learn the embedding from the first-order interactions. The representation and similarity information learned from the first-order interactions are not comprehensive enough, limiting the detection task. To this end, we propose a novel shilling attack detection model by fusing hypergraph spectral features (SpDetector). The proposed model combines the explicit and implicit features to balance the effectiveness and generality and deal with the high order relationships by hypergraphs-based embedding. From the implicit perspective, SpDetector constructs user hypergraphs and item hypergraphs for the high-order relationships hidden in the interaction and extracts spectral features from hypergraphs to capture high-order similarity for users and items, respectively. From the explicit perspective, it extracts two kinds of explicit features: item similarity offsets (ISO) based on item spectral features and rating prediction errors (RPE), for all users as their distinct capability of distinguishing fake users. Finally, the SpDetector learns to distinguish fake users by training a deep neural network with those features. Experiments conducted on MovieLens and Amazon datasets show that SpDetector outperforms state-of-the-art detection models.
Read More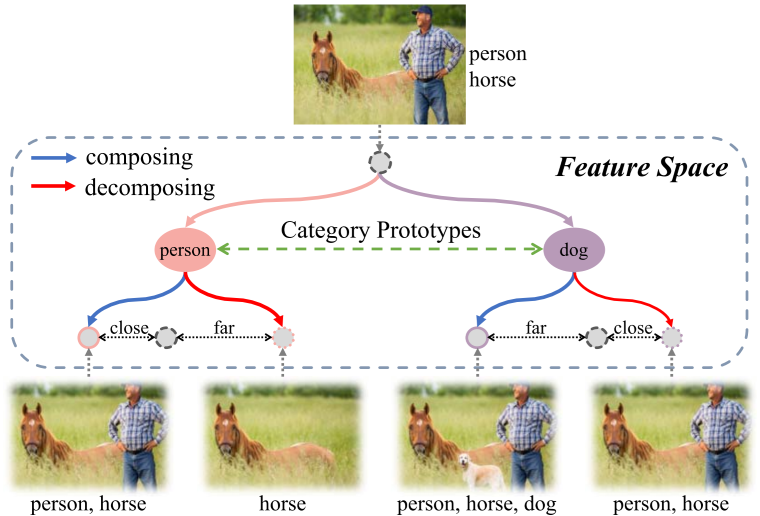
Multi-label Image Classification via Category Prototype Compositional Learning
Fengtao Zhou*, Sheng Huang#, Bo Liu, Dan Yang
IEEE Transactions on Circuits and Systems for Video Technology (TCSVT, 2021)
Real-world images are often compositions of multiple objects with different categories, scales, poses and locations. Adding nonexistent objects to an image (composing) or removing existent objects from an image (decomposing) leads to higher discrepancy in appearance, which reveals an important but long-neglected compositional nature of multi-label images. In light of this observation, we propose a novel end-to-end compositional learning framework named Category Prototype Compositional Learning (CPCL) to model such compositional nature for multi-label image classification. In CPCL, each image is represented by a collection of category-related features used to eliminate the negative effects from location information. Then, a compositional learning module is introduced to compose and decompose the category-related features with their corresponding category prototypes, which are derived from the semantic representations of categories. If the image has the given object, the output after composing should be closer to the original input than the output after decomposing. Contrarily, if the image does not have the given object, the output after decomposing should be closer to the original input than the output after composing. We introduce the Transformed Appearance Distance (TAD) to measure the appearance change between the composed and decomposed features relative to the category-related features with respect to each category. Finally, multi-label image classification is accomplished by performing a TAD-based metric learning. Experimental results on three multi-label image classification benchmarks, i.e. , NUS-WIDE, MS-COCO and VOC 2007, validate the effectiveness and superiority of our work in comparison with the state-of-the-arts. The source codes of our model have been released on https://github.com/ZFT-CQU/CPCL .
Read More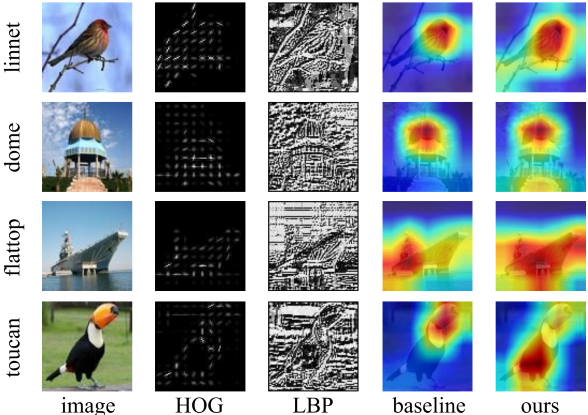
Generally Boosting Few-shot Learning with Handcrafted Features
Yi Zhang*, Sheng Huang#, Fengtao Zhou
ACM International Conference on Multimedia (ACM MM, 2021)
Existing Few-Shot Learning (FSL) methods predominantly focus on developing different types of sophisticated models to extract the transferable prior knowledge for recognizing novel classes, while they almost pay less attention to the feature learning part in FSL which often simply leverage some well-known CNN as the feature learner. However, feature is the core medium for encoding such transferable knowledge. Feature learning is easy to be trapped in the over-fitting particularly in the scarcity of the training data, and thereby degenerates the performances of FSL. The handcrafted features, such as Histogram of Oriented Gradient (HOG) and Local Binary Pattern (LBP), have no requirement on the amount of training data, and used to perform quite well in many small-scale data scenarios, since their extractions involve no learning process, and are mainly based on the empirically observed and summarized prior feature engineering knowledge. In this paper, we intend to develop a general and simple approach for generally boosting FSL via exploiting such prior knowledge in the feature learning phase. To this end, we introduce two novel handcrafted feature regression modules, namely HOG and LBP regression, to the feature learning parts of deep learning-based FSL models. These two modules are separately plugged into the different convolutional layers of backbone based on the characteristics of the corresponding handcrafted features to guide the backbone optimization from different feature granularity, and also ensure that the learned feature can encode the handcrafted feature knowledge which improves the generalization ability of feature and alleviate the over-fitting of the models. Three recent state-of-the-art FSL approaches are leveraged for examining the effectiveness of our method. Extensive experiments on miniImageNet, CIFAR-FS and FC100 datasets show that the performances of all these FSL approaches are well boosted via applying our method on all three datasets.
Read More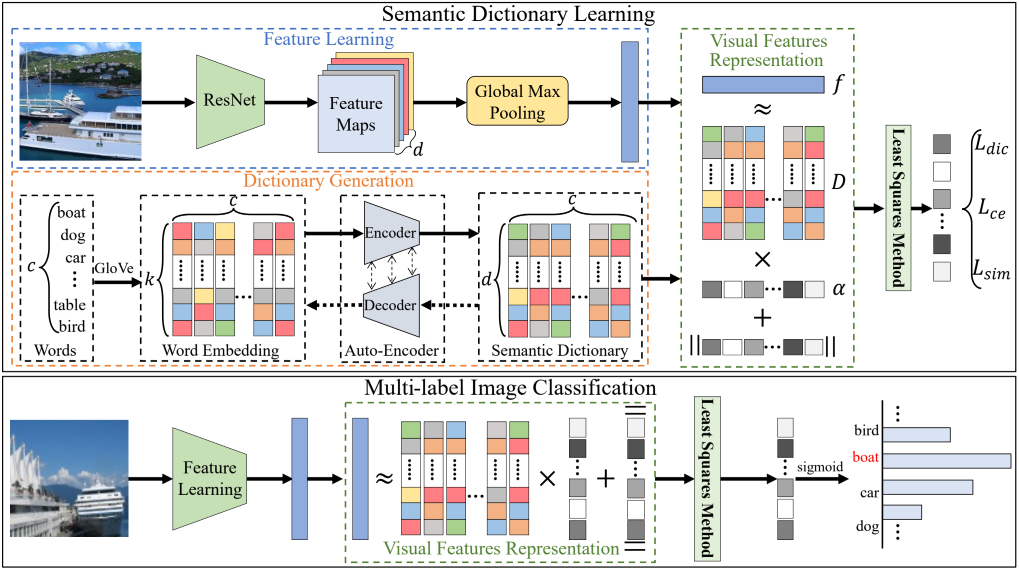
Deep Semantic Dictionary Learning for Multi-label Image Classification
Fengtao Zhou*, Sheng Huang#, Yun Xing
Proceedings of the AAAI Conference on Artificial Intelligence (AAAI, 2021)
Compared with single-label image classification, multi-label image classification is more practical and challenging. Some recent studies attempted to leverage the semantic information of categories for improving multi-label image classification performance. However, these semantic-based methods only take semantic information as type of complements for visual representation without further exploitation. In this paper, we present an innovative path towards the solution of the multi-label image classification which considers it as a dictionary learning task. A novel end-to-end model named Deep Semantic Dictionary Learning (DSDL) is designed. In DSDL, an auto-encoder is applied to generate the semantic dictionary from class-level semantics and then such dictionary is utilized for representing the visual features extracted by Convolutional Neural Network (CNN) with label embeddings. The DSDL provides a simple but elegant way to exploit and reconcile the label, semantic and visual spaces simultaneously via conducting the dictionary learning among them. Moreover, inspired by iterative optimization of traditional dictionary learning, we further devise a novel training strategy named Alternately Parameters Update Strategy (APUS) for optimizing DSDL, which alternately optimizes the representation coefficients and the semantic dictionary in forward and backward propagation. Extensive experimental results on three popular benchmarks demonstrate that our method achieves promising performances in comparison with the state-of-the-arts. Our codes and models have been released.
Read More